n8n-Connector
Der Entity-Enricher-Community-Node für n8n ermöglicht es Ihnen, automatisierte Anreicherungs-Pipelines mit einem visuellen Drag-and-Drop-Editor zu erstellen. Verbinden Sie sich mit über 400 Apps, ohne Code zu schreiben.
Installation
Installieren Sie den Community-Node in Ihrer n8n-Instanz:
npm install n8n-nodes-entity-enricher
Oder installieren Sie über die n8n-Oberfläche: Gehen Sie zu Einstellungen → Community Nodes und suchen Sie nach n8n-nodes-entity-enricher.
Voraussetzungen
ent_XXXXXXXXXXXX.https://entityenricher.ai oder Ihre selbst gehostete URL).Verfügbare Operationen
Der Konnektor stellt 10 Operationen über 6 Ressourcenkategorien bereit:
| Ressource | Vorgang | Beschreibung |
|---|---|---|
| Enrichment | Enrich Entity | Reichern Sie eine einzelne Entität mit einem oder mehreren KI-Modellen an. Streamt Ergebnisse per SSE mit Echtzeit-Fortschritt. |
| Enrichment | Batch Enrich | Reichern Sie alle Eingabeelemente als einen einzigen Batch an. Parallele Verarbeitung mit Fortschrittsverfolgung pro Entität. |
| Schema | List Schemas | Verfügbare gespeicherte Schemas zur Auswahl in Anreicherungs-Workflows auflisten. |
| Schema | Get Schema Details | Vollständigen Schema-Inhalt mit extrahierten Schlüsseleigenschaften für ein bestimmtes Schema abrufen. |
| Record | List Records | Fragen Sie Anreicherungs-Records mit Typ- und Erfolgsfiltern ab. Paginierte Ergebnisse. |
| Record | Get Record | Ein bestimmtes Enrichment-Ergebnis anhand der ID mit vollständiger strukturierter Ausgabe abrufen. |
| Fusion | Merge Results | Ergebnisse aus mehreren Enrichment-Records fusionieren – mit optionaler LLM-Arbitrierung. |
| Attachment | Add Attachment | Laden Sie eine Binäreigenschaft aus dem Eingabeelement hoch (multipart) und erhalten Sie deren Attachment-ID. |
| Attachment | Delete Attachment | Einen Anhang anhand der ID löschen – ein praktischer Aufräumschritt nach der Anreicherung. |
| Configuration | Get Options | Rufen Sie verfügbare Modelle, Sprachen, Strategien und Tarifgrenzen für die dynamische Konfiguration ab. |
Anreicherung einzelner Entitäten
Der einfachste Workflow: bei neuen Daten auslösen, eine einzelne Entität anreichern und das Ergebnis an Ihr Ziel übertragen. Der Knoten wartet, bis die vollständige Anreicherung abgeschlossen ist, bevor er die strukturierte Ausgabe weitergibt.
Beispiel-Workflow — Anreicherung einer einzelnen Entität:
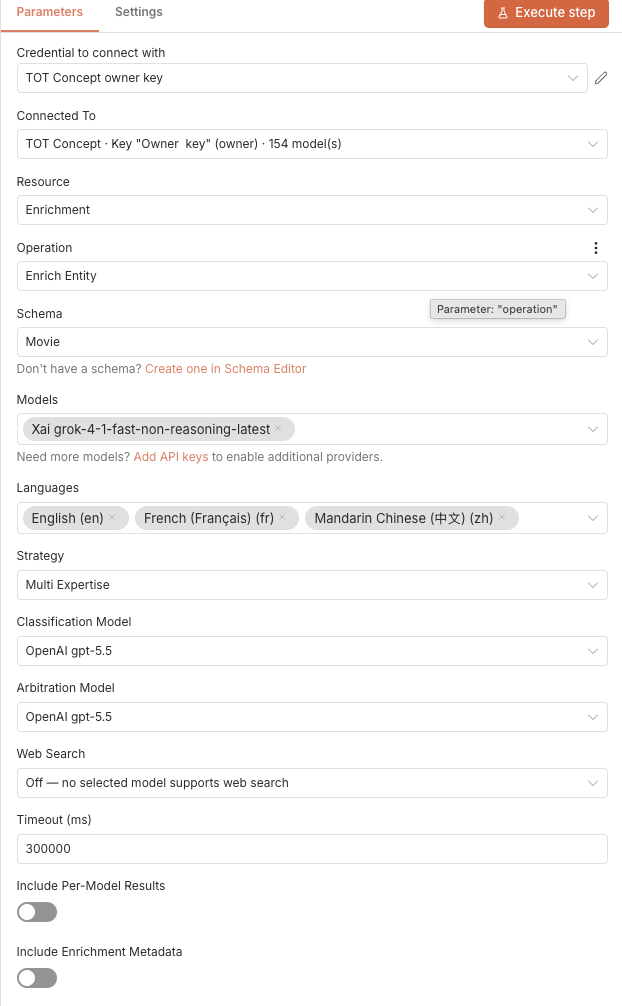
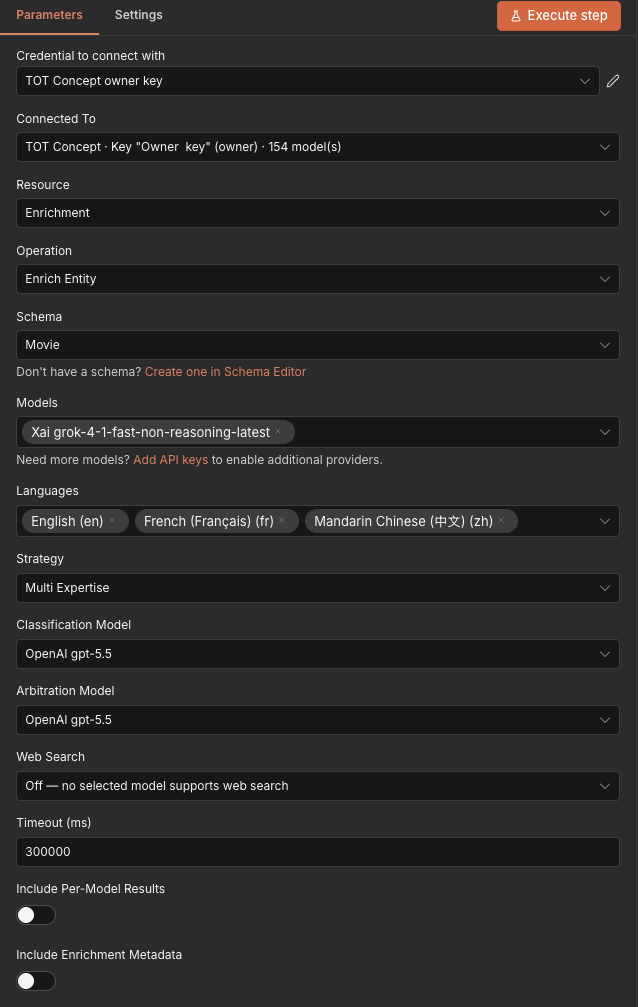
Node-Konfiguration – Operation „Enrich Entity“:
Konfiguration
Wählen Sie ein Schema aus dem dynamischen Dropdown, wählen Sie ein oder mehrere Modelle und geben Sie Entitätsdaten als Schlüssel-Wert-Felder an. Der Node füllt die Suchschlüsselfelder automatisch basierend auf dem ausgewählten Schema.
Zu den optionalen Einstellungen gehören Strategie (Single-Pass oder Multi-Expertise), Sprachen für mehrsprachige Ausgabe, Classification-Modell zur Verifizierung des Entity-Typs, Arbitration-Modell zur Konfliktlösung zwischen mehreren Modellen sowie Antwort-Schema- / strikte strukturierte Ausgabe-Schalter, die eine schemakonforme Ausgabe auf fähigen Modellen erzwingen.
Geben Sie ein Feld Attachment IDs an (kommagetrennte UUIDs aus vorherigen Add-Attachment-Aufrufen), um Quelldokumente in die Anreicherung einzuspeisen – ebenfalls bei Batch Enrich verfügbar.
Batch-Anreicherung
Verarbeiten Sie alle Eingabeelemente als einen einzigen Batch. Ideal zum Anreichern von Listen aus Tabellen, Datenbanken oder API-Antworten. Alle Entitäten werden parallel mit anbieterspezifischer Ratenbegrenzung verarbeitet.
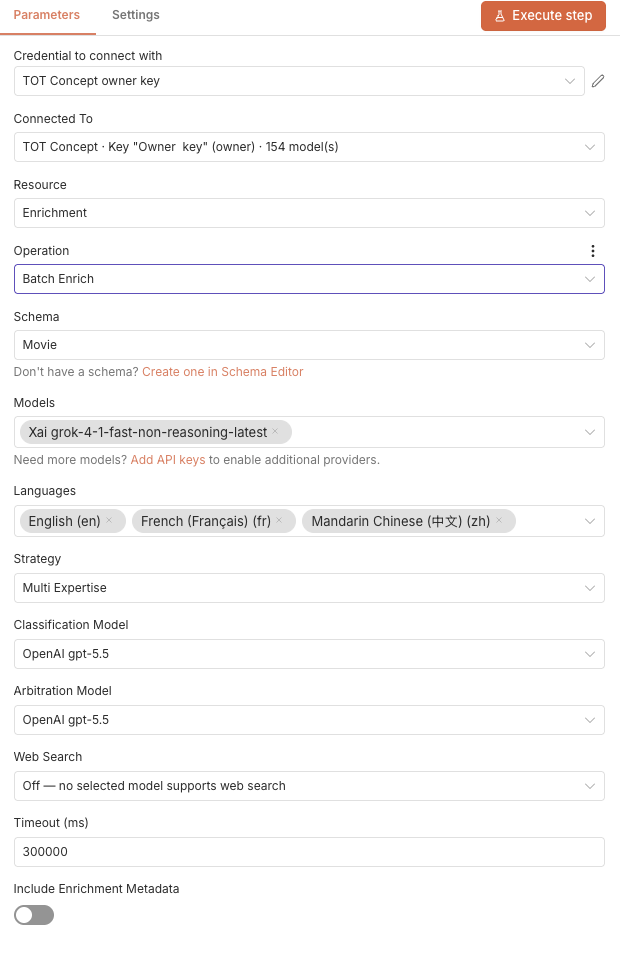
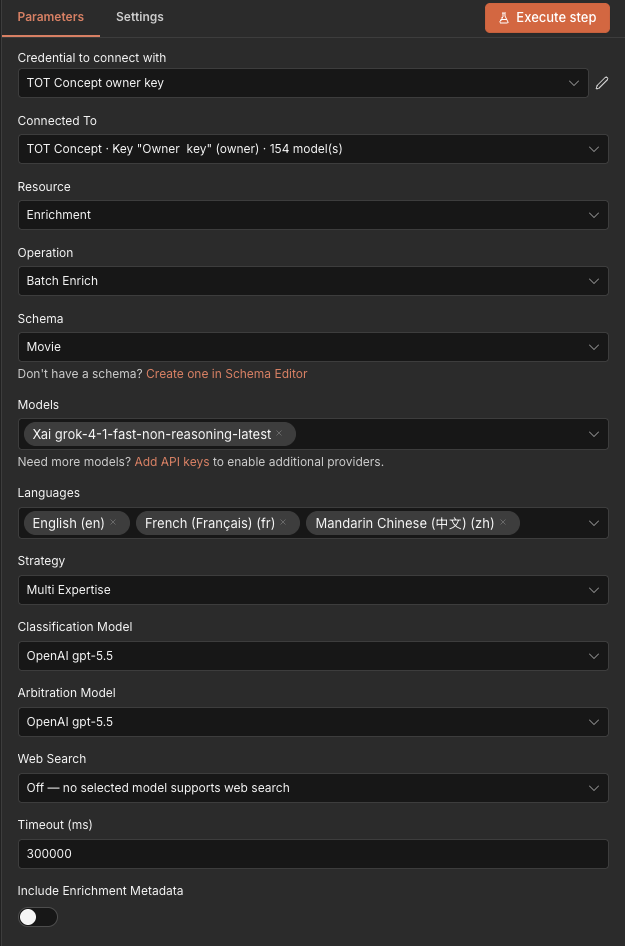
Node-Konfiguration – Operation „Batch Enrich“:
So funktioniert der Batch-Modus
- Elemente sammeln – Der Knoten sammelt alle Eingabeelemente vom vorherigen Knoten (z. B. Zeilen aus einer Tabelle).
- Batch-Job starten — Alle Entitäten werden über
POST /api/batch/startübermittelt und parallel verarbeitet. - Fortschritt streamen — Der Node verarbeitet den SSE-Stream, bis alle Entitäten abgeschlossen sind oder das Zeitlimit erreicht wird.
- Ausgabeergebnisse — Ein Ausgabeelement pro Entität mit den angereicherten strukturierten Daten, bereit für die Weiterverarbeitung.
Wichtige Funktionen
Dynamische Dropdowns
Die Auswahlfelder für Schema, Modell, Sprache und Strategie rufen die Optionen zum Konfigurationszeitpunkt aus Ihrer Entity Enricher-Instanz ab.
SSE-Streaming
Anreicherungsvorgänge konsumieren den SSE-Stream in Echtzeit und warten auf den Abschluss, bevor sie Ergebnisse an den nächsten Node zurückgeben.
Automatisch fortsetzen
Wenn die Pre-Flight-Klassifizierung eine Nichtübereinstimmung erkennt, fährt der Connector automatisch fort (n8n-Workflows sind nicht interaktiv).
Konfigurierbares Timeout
Standard-Timeout von 300 Sekunden pro Anreicherungsaufruf, pro Node anpassbar für große Schemas oder langsame Modelle.
Multi-Modell-Unterstützung
Wählen Sie mehrere Modelle pro Anreicherung. Wenn 2 oder mehr Modelle verwendet werden, werden die Ergebnisse automatisch fusioniert.
Ausgabe standardmäßig bereinigen
Standardmäßig enthält die Ausgabe nur die angereicherten Datenfelder. Schalten Sie „Anreicherungs-Metadaten einschließen“ ein, um Kosten, Tokens, Fusion-Details und Record-IDs hinzuzufügen.
Ausgabe pro Modell
Optional die einzelnen Modellergebnisse zusätzlich zum fusionierten Ergebnis für einen nachgelagerten Vergleich ausgeben.
Kenntnis der Planlimits
Modell- und Sprach-Dropdowns zeigen Tariflimits an, sofern konfiguriert. HTTP-402-Fehler aus der Kontingentdurchsetzung werden als klare, umsetzbare Meldungen mit Limitdetails dargestellt. Die Metadatenausgabe enthält die aktuellen Tariflimits für das nachgelagerte Routing.
Workflow-Ideen
Gängige Muster zum Erstellen von Anreicherungs-Pipelines mit n8n: